Selected Publications
Below, I use “^” to indicate the student collaborator that I mentored during whose internship or during an university collaboration.
[Google Scholar] [DBLP]
1. Hand, Gesture, and Human Pose
 |
Learning Dynamics via Graph Neural Networks for Human Pose Estimation and Tracking
Yiding Yang^, Zhou Ren, Haoxiang Li, Chunluan Zhou, Xinchao Wang, and Gang Hua
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[PDF]
Temporal Keypoint Matching and Refinement Network for Pose Estimation and Tracking
Chunluan Zhou, Zhou Ren, and Gang Hua
In IEEE European Conference on Computer Vision (ECCV), 2020.
[PDF]
3D Hand Shape and Pose Estimation from a Single RGB Image
Liuhao Ge^, Zhou Ren, Yuncheng Li, Zehao Xue, Yingying Wang, Jianfei Cai, Junsong Yuan
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019 (Oral).
[PDF][supplementary][video][code][dataset]
End-to-End 3D Hand Pose Estimation from Stereo Cameras
Yuncheng Li, Zehao Xue, Yingying Wang, Liuhao Ge, Zhou Ren, Jonathan Rodriguez
In British Machine Vision Conference (BMVC), 2019 (Oral).
[PDF]
Point-to-Point Regression PointNet for 3D Hand Pose Estimation
Liuhao Ge^, Zhou Ren, and Junsong Yuan
In European Conference on Computer Vision (ECCV), 2018.
[PDF]
Robust Part-based Hand Gesture Recognition Using Kinect Sensor
Zhou Ren, Junsong Yuan, Jingjing Meng, and Zhengyou Zhang
In IEEE Trans. on Multimedia (TMM), 15(5), 1110-1120, 2013.
* Winner of 2016 IEEE Trans. on Multimedia Prize Paper Award (Best Paper Award)*
[PDF][Bibtex][NTU-Microsoft-Kinect HandGesture Dataset]
Robust Hand Gesture Recognition based on Finger-Earth Mover’s Distance with a Commodity Depth Camera
Zhou Ren, Junsong Yuan, and Zhengyou Zhang
In ACM Multimedia (ACM MM), Scottsdale, Arizona, USA, Nov. 28-Dec. 1, 2011.
*The most cited paper in ACM MM 2011*
[PDF][Bibtex][NTU-Microsoft-Kinect HandGesture Dataset][Demo]
Robust Hand Gesture Recognition with Kinect Sensor
Zhou Ren, Jingjing Meng, Junsong Yuan, and Zhengyou Zhang
In ACM Multimedia (ACM MM), Scottsdale, Arizona, USA, Nov. 28-Dec. 1, 2011.
*The 2nd most cited paper in ACM MM 2011*
[PDF][Bibtex][Demo]
2. Object Detection, Action Detection, and Person ReID
 |
Uncertainty-Based Spatial-Temporal Attention for Online Action Detection
Hongji Guo^, Zhou Ren, Yi Wu, Gang Hua, and Qiang Ji
In European Conference on Computer Vision (ECCV), 2022.
[PDF]
TxVAD: Improved Video Action Detection by Transformers
Zhenyu Wu^, Zhou Ren, Yi Wu, Zhangyang Wang, and Gang Hua
In ACM Multimedia, 2022.
[PDF]
Temporal Structure Mining for Weakly Supervised Action Detection
Tan Yu^, Zhou Ren, Yuncheng Li, Enxu Yan, Ning Xu, and Junsong Yuan
In International Conference on Computer Vision (ICCV), 2019.
[PDF]
Deep Regionlets: Blended Representation and Deep Learning for Generic Object Detection
Hongyu Xu^, Xutao Lv, Xiaoyu Wang, Zhou Ren, and Rama Chellappa
In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2019.
[PDF]
Deep Regionlets for Object Detection
Hongyu Xu^, Xutao Lv, Xiaoyu Wang, Zhou Ren, and Rama Chellappa
In European Conference on Computer Vision (ECCV), 2018.
[PDF]
3. Multi-Modal Joint Understanding, Vision and Language
 |
SibNet: Sibling Convolutional Encoder for Video Captioning
Sheng Liu^, Zhou Ren, and Junsong Yuan;
In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2019.
[PDF]
Streamlined Dense Video Captioning
Jonghwan Mun^, Linjie Yang, Zhou Ren, Ning Xu, and Bohyung Han
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019 (Oral).
[PDF][supplementary]
SibNet: Sibling Convolutional Encoder for Video Captioning
Sheng Liu^, Zhou Ren, and Junsong Yuan
In ACM Multimedia, 2018 (Oral)
[PDF]
Multiple Instance Visual-Semantic Embedding
Zhou Ren, Hailin Jin, Zhe Lin, Chen Fang, and Alan Yuille
In British Machine Vision Conference (BMVC), 2017 (Oral)
[PDF][Supplementary][Bibtex][Video]
Deep Reinforcement Learning-based Image Captioning with Embedding Reward
Zhou Ren, Xiaoyu Wang, Ning Zhang, Xutao Lv, and Li-Jia Li
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017 (Oral)
*Best Student Paper Award Nomination*
[PDF][Bibtex][Talk slides][Poster][Video]
4. Adversarial Machine Learning
 |
Adversarial Attacks and Defences Competition
Alexey Kurakin, et. al.
In a book chapter from the NIPS 2017 Competition Book, Springer 2018
[PDF]
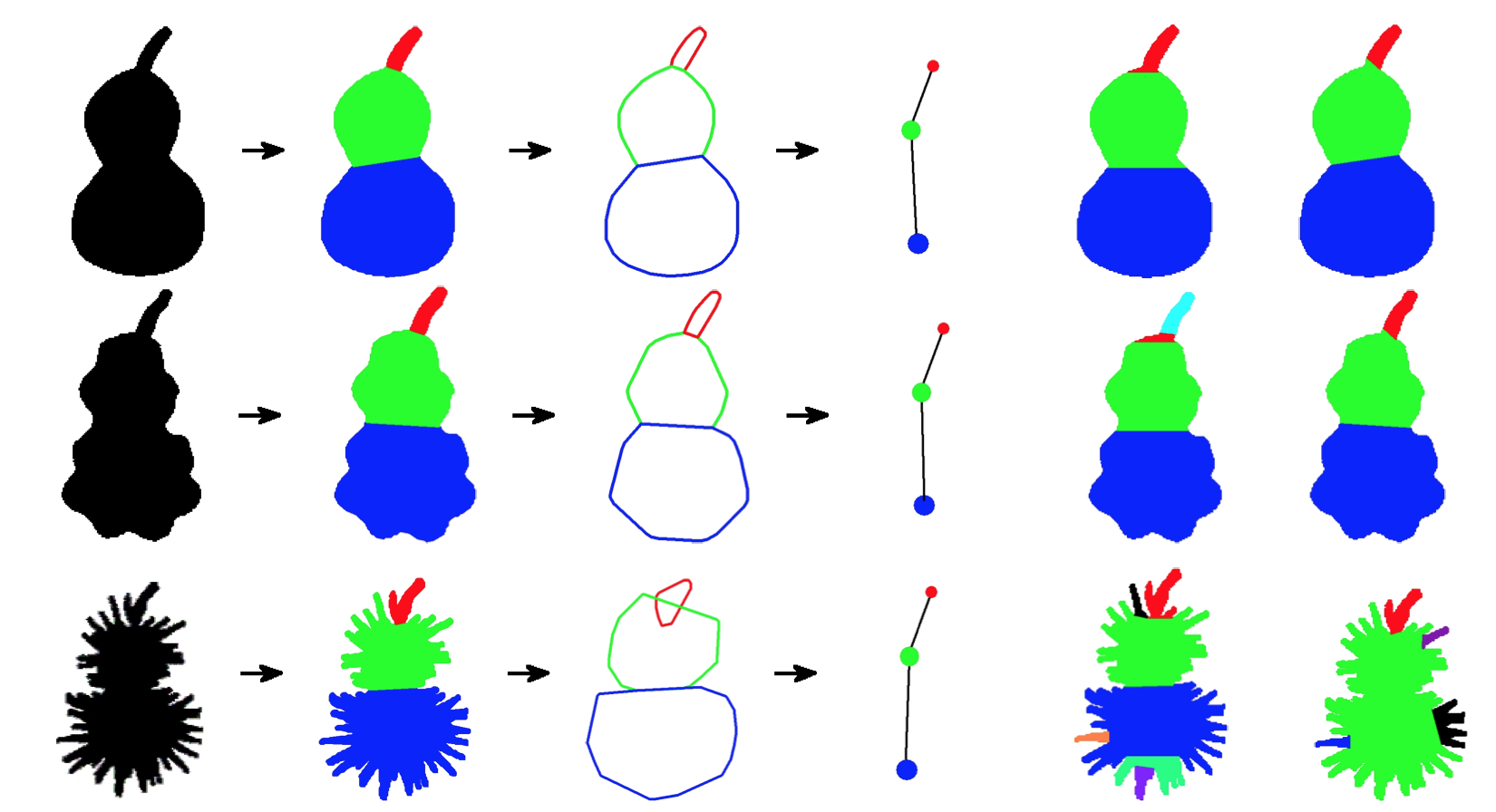
5. Shape Representation, and Shape Coding
 |
6. Medical Image Processing
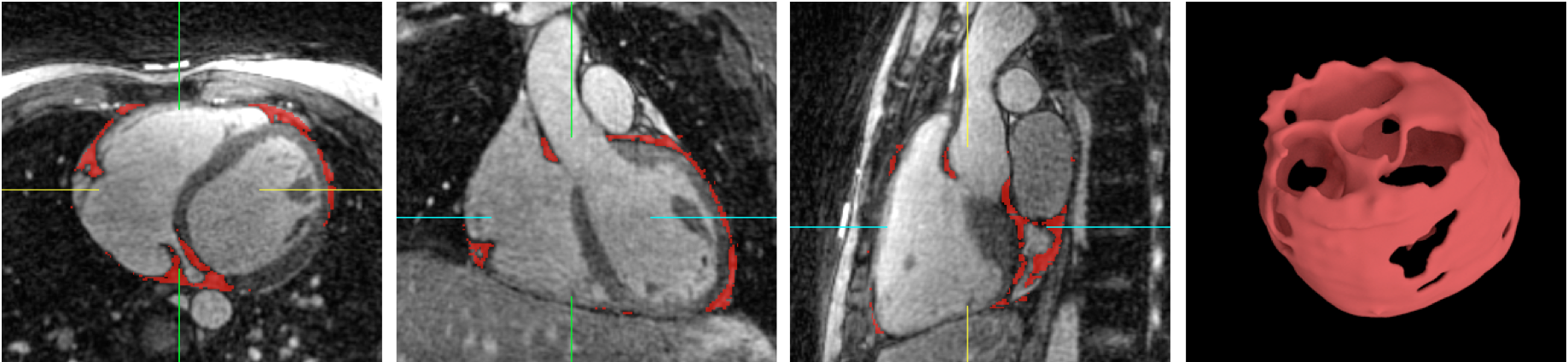 |
Automated Pericardial Fat Quantification from Coronary Magnetic Resonance Angiography: A Feasibility Study
Xiaowei Ding, Jianing Pang, Zhou Ren, Mariana Diaz-Zamudio, Chenfangfu Jiang, Zhaoyang Fan, Daniel Berman, Debiao Li, Demetri Terzopoulos, Piotr Slomka, and Damini Dey
In Journal of Medical Imaging, 2016.
[PDF][Bibtex]
Automated Pericardial Fat Quantification from Coronary Magnetic Resonance Angiography
Xiaowei Ding, Jianing Pang, Zhou Ren, Mariana Diaz-Zamudio, Daniel Berman, Debiao Li, Demetri Terzopoulos, Piotr Slomka, and Damini Dey
In Medical Image Understanding and Analysis (MIUA), 2015 (Oral).
[PDF][Bibtex]